StackStorm + Nagios
Event-driven Automation (Part1)
This is part one of the Stackstorm + Nagios event-driven Automation series, you can find part two of this series here.
Introduction
In an earlier post, we created and executed our first action in Stackstorm. The action didn't do much, however. It was just a simple script that printed a message.
In this article we'll ramp things up a bit and execute an action based upon a "trigger". A "trigger" is a Stackstorm term that pretty much does what you expect! A trigger will get...triggered and then execute an action.
But what problem are we actually trying to solve?
As you may know, we operate a lab environment for students taking our courses. Because of this, devices occasionally get taken completely offline. This happens infrequently, but not so infrequently that automatic recovery wouldn't be nice. Enter StackStorm!
Consequently, we want Stackstorm to detect and fix failed network devices. In particular, if any of our Arista vEOS switches go down, we want StackStorm to attempt to recover them.
Since there are a lot of moving parts here, we will need multiple articles to cover this process. In this article, we'll cover the integration of Nagios to StackStorm. In the next article, we will expand upon the system to actually use alerts to recover a failed device (using a Nornir recovery script).
Enough with the preamble, let's dive into this!
StackStorm: Triggers and Rules
In order to "automagically" recover a failed Arista switch, we first need to know that it has gone offline.
In our environment, we have a pretty straightforward Nagios deployment with basic email alerts (and some PagerDuty alerts for more critical services).
Happily for us there is a StackStorm-Nagios pack that we can install. This pack is hosted on the StackStorm Exchange, and is easily installed using the st2 CLI tools:
$ st2 pack install nagios --python3
For the "nagios" pack, the following content will be registered:
actions | 0
rules | 6
sensors | 0
aliases | 0
triggers | 1
Installation may take a while for packs with many items.
[ succeeded ] download pack
[ succeeded ] make a prerun
[ succeeded ] install pack dependencies
[ succeeded ] register pack
+-------------+-------------------------------+
| Property | Value |
+-------------+-------------------------------+
| name | nagios |
| description | Nagios Monitoring integration |
| version | 0.2.2 |
| author | StackStorm, Inc. |
+-------------+-------------------------------+You can see the virtual environment that st2 created in the "/opt/stackstorm/virtualenvs" directory. Here we can confirm we are indeed using Python3.6.8 for our Nagios pack:
$ /opt/stackstorm/virtualenvs/nagios/bin/python --version
Python 3.6.8You can find the repository for this Pack here.
What exactly is this StackStorm pack going to do for us?
Basically, it allows StackStorm to "listen" for Nagios events (such as a device going down).
The GitHub repository, linked above, provides pretty clear instructions for how to configure this on the Nagios host. The Nagios server needs to have two files added to it. The first is "st2service_handler.py" which is a Python script that Nagios will execute when "events" happen. The second is "st2service_handler.yaml" which is a configuration file that the Python script uses.
The "st2service_handler.py" Python script will execute web requests to the StackStorm server when certain Nagios events happen. These web requests sent from the Nagios server to StackStorm will ultimately generate additional actions in StackStorm.
As for the Python script itself, we only need to install it and ensure that it is executable.
$ chmod + x /usr/local/nagios/libexec/st2service_handler.pyThe YAML file, however, will need to be edited. We must add our credentials and also our StackStorm server's URL:
---
# st2 credentials. you can either use username/password combo
# or specify an API key or unauthed.
st2_api_key: ""
st2_username: "st2admin"
st2_password: "password"
st2_api_base_url: "https://stackstorm.someplace.com/api/v1/"
st2_auth_base_url: "https://stackstorm.someplace.com/auth/v1/"
unauthed: False
ssl_verify: Falsest2service_handler.pyNow that we have the Python script and YAML file installed on the Nagios server, we can generate test messages. Before we do this, however, we need to set up StackStorm to do something when a message arrives from Nagios. In order to accomplish this, we need to create a StackStorm "rule".
A StackStorm "rule" is what you'd probably expect—guidance for what to do in a given situation.
In our case we will start off small; we will have StackStorm simply run our "hello" action when a Nagios alert is received.
A rule definition is written in YAML and contains metadata including which pack the rule belongs to, what the rule is called, and trigger information. The rule definition also defines when this rule should be executed, and what action should be taken in response.
Back on our StackStorm host, let's start with the following for our rule definition:
---
pack: super_cool_python
ref: super_cool_python.nagios_trigger
name: nagios_trigger
uid: rule:super_cool_python:nagios_trigger
tags: []
type:
ref: standard
parameters: {}
enabled: true
trigger:
type: nagios.service_state_change
ref: nagios.service_state_change
description: Trigger type for nagios service state change event.
parameters: {}
metadata_file: ''
context:
user: st2admin
criteria:
trigger.state:
pattern: "^CRITICAL|DOWN$"
type: regex
trigger.state_type:
pattern: HARD
type: eq
action:
ref: super_cool_python.hello_st2
description: say hello!This looks like a lot of information.
The most important item in the above YAML is specifying the trigger. In this case, we are pointing to "nagios.service_state_change" which came with the Nagios pack that we installed.
For the "criteria", we are looking for either the "CRITICAL" or "DOWN" states and a state type of "HARD". These are normal Nagios alert states and tell us the device is down and has been down for a while (as opposed to an intermittent issue).
Lastly, we tell st2 what action to take in response to the trigger.
Here, we'll use the simple "hello" action that we created previously (see our earlier StackStorm Hello World article).
This StackStorm rule should live in our pack so that it gets installed anytime the pack is installed. Common convention is to have a "rules" directory inside the pack, so that is what we'll do. We also add that rule file to git so that we can reinstall our pack.
$ mkdir ~/super_cool_python/rules
$ touch ~/super_cool_python/rules/nagios_trigger.yaml
$ cd ~/super_cool_python/
$ git add rules/
$ git commit -m "updating very cool st2 pack"
$ st2 pack install ~/super_cool_python/ --python3We should now be able to see our rule using the st2 cli:
$ st2 rule list | grep super_cool_python
| super_cool_python.nagios_trigger | super_cool_python | | True |Nice!
Next we need to test that the rule actually runs when we send a notification from Nagios. Happily, we can test this without having to bring down any of our devices!
Testing the Trigger and Rule
From our Nagios host we can test this trigger/rule combo by executing the "st2service_handler.py" script and passing in the appropriate arguments. This script expects arguments in the following order (and it requires the YAML config file as the very first argument):
- event_id
- service
- state
- state_id
- state_type
- attempt
- host
In our st2 rule we are stating that "if the state is either CRITICAL or DOWN and the state_type is HARD", then we should execute our action. Running the script and passing in the appropriate arguments should cause our trigger to be detected:
$ python st2service_handler.py st2service_handler.yaml 1 testing CRITICAL 1 HARD 1 my_super_cool_routerWe can then see if our rule really did execute with the st2 cli:
$ st2 rule-enforcement list
+------+-------------------+-----------------+---------+----------------+
| id | rule.ref | trigger_inst_id | exec_id | enforced_at |
+- ----+-------------------+-----------------+---------+----------------+
| 0f84 | super_cool_python | 0f7f | 0f83 | 2019-08-05T22: |
| | nagios_trigger | | | 12:43.543600Z |Note, the above IDs were abbreviated to make the table more readable on the web.
Sure enough we can see that our rule did indeed execute!
We can also look at the actual action executions (this is the action that StackStorm takes, after the trigger condition is detected):
$ st2 execution get 5d48a9db68770c546de40f83
id: 5d48a9db68770c546de40f83
status: succeeded (1s elapsed)
parameters: None
result:
exit_code: 0
result: Let's be friends!
stderr: ''
stdout: 'Hello Stackstorm, want to be friends?'We retrieved that execution-id from the output of the "rule-enforcement list".
Nagios and the ServiceHandler
At this point we have the integration between Nagios and StackStorm working for manual events. Next, we need to update the Nagios configuration such that it generates these StackStorm alerts. We do this by creating a custom command that Nagios will then invoke. In our case we have a simple commands file called "commands.cfg" where we've added the following:
define command{
command_name st2nagioshost
command_line /usr/local/nagios/libexec/st2service_handler.py /usr/local/nagios/libexec/st2service_handler.yaml "0" "NONE" "$HOSTSTATE$" "0" "$HOSTSTATETYPE$" "$HOSTATTEMPT$" "$HOSTNAME$"
}In this case, we had to do a bit of custom mapping. In other words, the "st2service_handler.py" is intended for Nagios service alerts and we needed it to handle Nagios host alerts. Consequently, we had to find the closest equivalent fields (Nagios host alerts fields mapped to the arguments that the st2 Python script was expecting).
Here are the values that we are passing in (the $VAR$ pattern are variables coming from Nagios):
- event_id -> 0; we don't really care what the event ID is
- service -> None; this is just for our generic host checking
- state -> $HOSTSTATE$; coming from Nagios: CRITICAL, UP, etc.
- state_id -> 0; we don't care what the state ID is
- state_type -> $HOSTSTATETYPE$; from Nagios: SOFT, HARD, etc.
- attempt -> $HOSTATTEMPT$; Nagios reach attempt number.
- host -> $HOSTNAME$; the device Nagios is monitoring.
Next we need to tell Nagios to execute this command when an alert is generated:
# "st2-generic-contact" invokes the "st2nagioshost" command which is
# the command that we defined in commands.cfg
define contact{
name st2-generic-contact
host_notification_period 24x7
host_notification_options d,u,r,f,s
host_notification_commands st2nagioshost
register 0
}
define contact{
contact_name stackstorm-base
use st2-generic-contact
alias Stack Storm
}
define contactgroup{
contactgroup_name stackstorm
alias StackStorm Contact Group
members stackstorm-base
}I've omitted a bit here for brevity, but this should cover the important bits.
We create a contact, in this case "st2-generic-contact", assign it a notification period, some options, and tell it to not "register" (as this is just a contact "template"). We then reference the "template" in our "stackstorm-base" contact, and finally put the "stackstorm-base" contact into our contact group called "stackstorm".
Finally, we need to assign this contact group to one or some or all of our hosts!
define host{
host_name super_cool_router
contact_groups stackstorm
}Again, I've omitted some Nagios specific items, but we can see that the host "super_cool_router" is assigned to the contact group "stackstorm". When a "host notification" occurs for "super_cool_router", Nagios will send an alert to StackStorm with the appropriate information included in the web request.
In the next article, we'll modify our st2 pack to execute the actual Arista switch recovery action.
You might also be interested in:
-
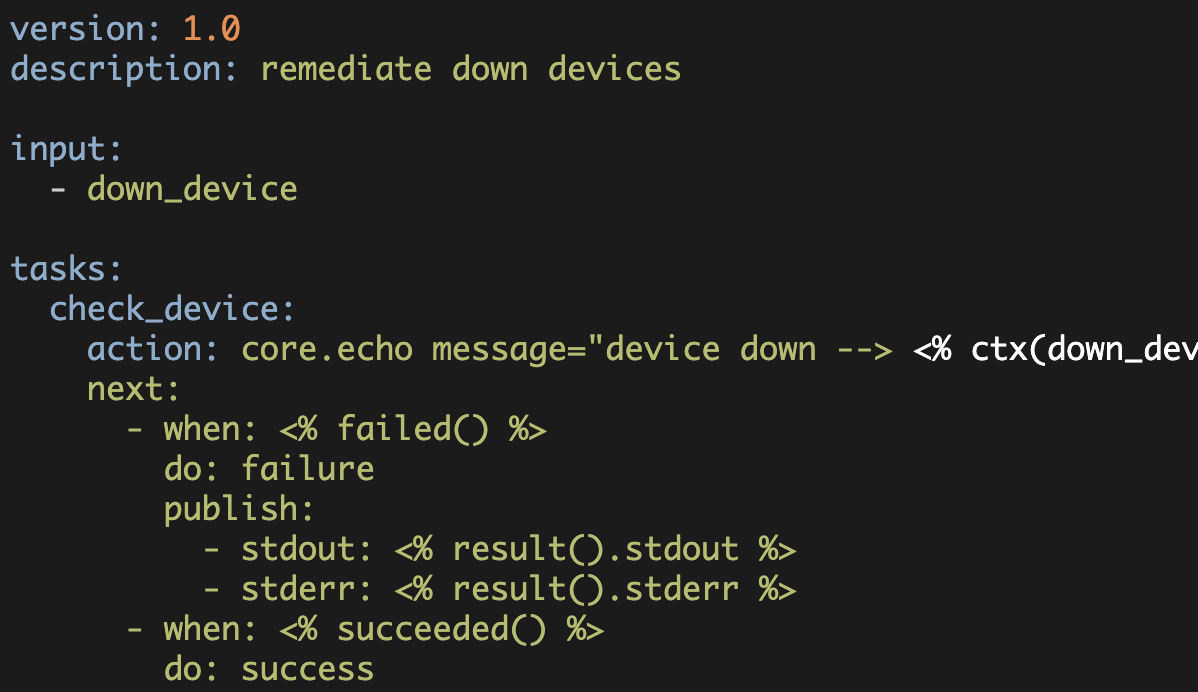
Stackstorm
StackStorm + Nagios event-driven Automation (Part2)
Previously, we configured Nagios to send a webhook to StackStorm.
-
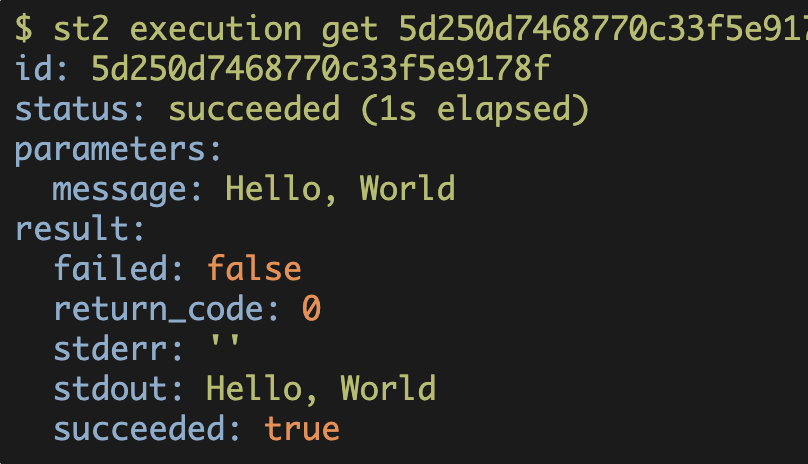
Stackstorm
StackStorm: Hello World
Writing scripts or playbooks is only one piece of the greater puzzle that is automation.
-
Nornir
An Introduction to Nornir
Recently David Barroso and others (including me) have created a new network automation framework named Nornir. The vast majority of the credit belongs to David, however.